


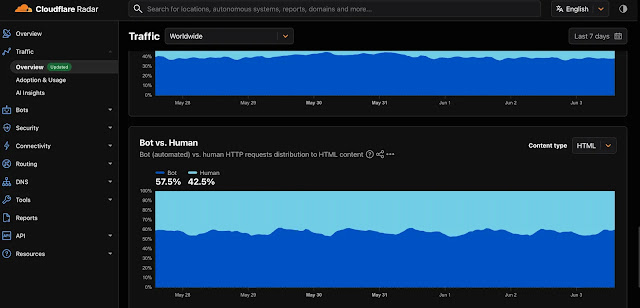
Lần đầu tiên trong lịch sử, các bot tự động đã chính thức vượt qua người dùng thật về **lưu lượng bot** trên internet toàn cầu, và sự thay đổi này đang tăng tốc nhanh hơn dự đoán của cả các chuyên gia hàng đầu. Dữ liệu từ Cloudflare Radar cho thấy các bot hiện chiếm đến 57.5% tổng số yêu cầu HTTP đến các trang HTML trên toàn cầu, trong khi lưu lượng truy cập do con người tạo ra đã giảm xuống chỉ còn 42.5%. Tình hình tại Hoa Kỳ thậm chí còn rõ nét hơn, với lưu lượng bot chiếm đến 71.5% tổng số yêu cầu web trong nước, nhấn mạnh mức độ tự động hóa do AI điều khiển đã thâm nhập sâu vào các thị trường kết nối nhất thế giới.
Sự chuyển dịch này không chỉ giới hạn ở một nguồn dữ liệu duy nhất. Báo cáo Bad Bot Report 2025 của Imperva đã độc lập xác nhận rằng lưu lượng truy cập tự động đã vượt ngưỡng 50% lần đầu tiên trong một thập kỷ, đạt 51% tổng lưu lượng web toàn cầu vào năm 2024. Mạng lưới của Cloudflare, vốn phục vụ khoảng 1/5 số trang web trên toàn thế giới, cũng cho thấy tỷ lệ phân chia bot-con người xấp xỉ 53% so với 47% đối với các yêu cầu HTML vào cuối năm 2025.
Tình hình Lưu lượng Bot Toàn cầu
Số liệu thống kê vượt trội
Matthew Prince, CEO của Cloudflare, trong buổi phát biểu tại SXSW đầu năm nay, đã dự đoán rằng lưu lượng bot sẽ vượt qua lưu lượng con người vào năm 2027. Tuy nhiên, dự đoán này đã đến sớm hơn lịch trình, phản ánh tốc độ phát triển chóng mặt của các tác nhân tự động trên internet.
Ông Prince đã nhấn mạnh sự khác biệt về quy mô giữa hành vi duyệt web của con người và AI. Một người mua sắm sản phẩm có thể truy cập năm trang web, trong khi một tác nhân AI thực hiện cùng một nhiệm vụ có thể truy vấn 5.000 trang web. Sự khác biệt này tạo ra một khối lượng lưu lượng truy cập khổng lồ.
“Sự việc này xảy ra nhanh hơn tôi dự đoán. Tôi nghĩ nó sẽ diễn ra vào cuối năm 2027, sau đó là đầu năm 2027, nhưng lưu lượng tác nhân đang tăng trưởng quá nhanh đến nỗi bot đã vượt qua lưu lượng truy cập của con người trực tuyến lần đầu tiên trong lịch sử Internet,” ông Prince chia sẻ trên nền tảng X.
Các số liệu này minh họa một sự thay đổi cơ bản trong cách internet hoạt động. Nền tảng web không còn là một không gian chủ yếu do con người tương tác mà đang dần trở thành một môi trường nơi máy móc và thuật toán chiếm ưu thế trong các hoạt động hàng ngày.
Sự trỗi dậy của AI và các tác nhân tự động
Mô hình này chủ yếu được thúc đẩy bởi các trình thu thập dữ liệu (AI scrapers), các trình thu thập dữ liệu để đào tạo mô hình ngôn ngữ lớn (LLM training crawlers) và các tác nhân tìm kiếm tự động được xây dựng dựa trên các mô hình như GPT của OpenAI, Claude của Anthropic và Gemini của Google. Lưu lượng truy cập do AI điều khiển đã tăng vọt 187% vào năm 2025, tăng nhanh gần tám lần so với hoạt động web của con người trong cùng kỳ.
Sự gia tăng đáng kể của các tác nhân AI không chỉ thể hiện khả năng tự động hóa mạnh mẽ mà còn cho thấy nhu cầu thu thập và xử lý dữ liệu ở quy mô lớn. Các LLM cần một lượng lớn thông tin để học hỏi và cải thiện, dẫn đến việc các bot này liên tục quét và lập chỉ mục các trang web, đóng góp vào tỷ lệ **lưu lượng bot** ngày càng cao. Điều này tạo ra một thách thức mới cho các nhà quản trị web và các chuyên gia **an ninh mạng**.
Ảnh hưởng An ninh Mạng từ Lưu lượng Bot Độc hại
Phân loại và Tác động An ninh
Sự bùng nổ của lưu lượng bot kéo theo những hệ lụy nghiêm trọng về bảo mật. Trong tổng số lưu lượng truy cập tự động, 37% được phân loại là độc hại, còn gọi là “bad bots” (bot độc hại), trong khi chỉ có 14% là các trình thu thập dữ liệu hợp pháp. Các bot độc hại này không chỉ đơn thuần là thu thập thông tin mà còn tham gia vào nhiều hoạt động có hại, từ việc thực hiện các cuộc tấn công DDoS, nhồi nhét thông tin đăng nhập (credential stuffing), scraping nội dung, cho đến gian lận quảng cáo và thăm dò lỗ hổng.
Các cuộc tấn công do bot độc hại gây ra có thể làm tê liệt hệ thống, đánh cắp dữ liệu nhạy cảm hoặc làm sai lệch thông tin. Ví dụ, các bot có thể được sử dụng để tự động thử hàng ngàn tên người dùng và mật khẩu bị đánh cắp nhằm chiếm đoạt tài khoản người dùng, tạo ra một **mối đe dọa mạng** đáng kể cho các dịch vụ trực tuyến. Sự phức tạp và tốc độ của các cuộc tấn công này đòi hỏi các giải pháp bảo mật phải liên tục được cải tiến.
Các nhà xuất bản và nhà quảng cáo hiện đang phải đối mặt với các số liệu phân tích bị bóp méo nghiêm trọng, vì bảng điều khiển lưu lượng truy cập phản ánh hành vi của máy móc thay vì sự tương tác thực sự của khán giả. Điều này ảnh hưởng đến việc đánh giá hiệu suất, phân bổ ngân sách và hiểu biết về hành vi người dùng, gây ra những tổn thất đáng kể về doanh thu và chiến lược.
Thách thức đối với Phát hiện và Phòng chống
Việc phân biệt giữa bot hợp pháp (như các trình thu thập thông tin của công cụ tìm kiếm) và bot độc hại ngày càng trở nên khó khăn. Các bot độc hại thường giả mạo hành vi của con người hoặc các bot hợp pháp để né tránh các biện pháp phát hiện truyền thống. Điều này đòi hỏi các hệ thống phòng thủ phải thông minh hơn, sử dụng AI và học máy để phân tích hành vi và ngữ cảnh thay vì chỉ dựa vào các mẫu chữ ký tĩnh.
Các tổ chức cần đầu tư vào các giải pháp quản lý bot tiên tiến, bao gồm tường lửa ứng dụng web (WAF) thế hệ mới, hệ thống phát hiện và phản ứng bot (Bot Detection and Response – BDR), và các công cụ phân tích hành vi người dùng (UBA). Mục tiêu là không chỉ chặn các bot rõ ràng là độc hại mà còn xác định và giảm thiểu tác động của các bot có hành vi đáng ngờ mà không ảnh hưởng đến người dùng hợp pháp.
Các Giải pháp và Hướng đi trong Tương lai
Khai thác và Phòng chống
Để ứng phó với tình hình này, các khung giao thức “pay-to-crawl” (trả tiền để thu thập dữ liệu) đang ngày càng trở nên phổ biến. Cloudflare đã thực hiện việc chặn các trình thu thập dữ liệu AI theo mặc định, trừ khi chúng bồi thường cho các nhà sáng tạo nội dung. Cách tiếp cận này giúp các nhà xuất bản kiểm soát tốt hơn ai có thể truy cập và sử dụng dữ liệu của họ, đồng thời tạo ra một mô hình doanh thu mới cho nội dung trực tuyến.
Cloudflare đã giới thiệu một sáng kiến được gọi là “AI Labyrinth” hoặc “AI Gateway” nhằm giúp các nhà phát triển và doanh nghiệp quản lý và kiểm soát tốt hơn quyền truy cập của các mô hình AI vào nội dung của họ. Thông qua việc yêu cầu AI phải “trả tiền” hoặc tuân thủ các điều khoản cụ thể để truy cập, các trang web có thể bảo vệ giá trị nội dung của mình trong bối cảnh “nền kinh tế tác nhân” đang phát triển.
Tham khảo thêm về cách Cloudflare tiếp cận vấn đề chặn AI: Cloudflare Unveils AI Labyrinth: A New Approach to Exhaust AI Crawlers.
Thích nghi với Nền kinh tế Tác nhân
Khi các tác nhân tự động, công cụ tìm kiếm do AI hỗ trợ và các pipeline LLM ngày càng phổ biến, tỷ lệ này sẽ chỉ càng nghiêng về phía tự động hóa. “Nền kinh tế tác nhân” không còn là dự báo của năm 2027; nó là thực tế hiện tại của internet, và cơ sở hạ tầng web, mô hình kiếm tiền cũng như kiến trúc bảo mật sẽ cần phải thích nghi phù hợp.
Sự thích nghi này bao gồm việc tái đánh giá các mô hình kinh doanh dựa trên quảng cáo, phát triển các giải pháp bảo mật nâng cao để đối phó với **lưu lượng bot** phức tạp hơn, và thiết lập các chính sách rõ ràng về việc sử dụng nội dung bởi AI. Các tổ chức cần chủ động trong việc phát triển chiến lược để quản lý và tận dụng sức mạnh của các tác nhân AI, đồng thời giảm thiểu các rủi ro do bot độc hại gây ra.
Đây là thời điểm quan trọng để các nhà phát triển web, chuyên gia bảo mật và chủ sở hữu nội dung cùng nhau định hình lại tương lai của internet. Việc hiểu rõ và kiểm soát **lưu lượng bot** sẽ là chìa khóa để đảm bảo một không gian mạng an toàn, hiệu quả và công bằng cho tất cả mọi người.







